adg的搭建一般问题不大,遇到问题最多的应该是实时同步。
1. adg同步原理
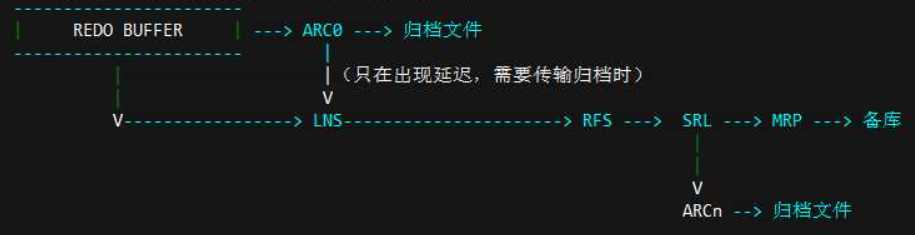
1.1. 传输流程:
- 主库的LGWR进程写自己的在线重做日志(ORL)
- 主库的DataGuard进程LNS(LogWriter Network Process)从SGA的redo buffer里读redo信息然后通过网络服务传输给备用数据库。
- 由LNS传输的redo记录由备用数据库的另外一个DataGuard进程RFS(Remote File Server)接收。
- RFS接收redo记录之后将其写入备用重做日志(SRL)。
1.2. ARCH or LNS
在备库故障或网络中断期间,DataGuard在主库上使用ARCH进程连续ping备库来确定其状态。当与备库的通信还原后,ARCH ping进程会查询备库控制文件来确定备用数据库最后一个接收到的完整日志文件,以此确定需要从主库传输哪些日志文件来重新同步备库,然后开始使用ARCH进程传输相应文件。
Oracle10g开始默认归档进程数为2,从而在自动处理日志文件间隔时,不影响主数据库的归档操作。
在接下来执行日志切换时,LNS会试图连接备用数据库,成功后也会开始传输当前重做数据,同一时间ARCH进程在后台处理日志文件间隔。
当应用进程(MRP)赶上进度之后,不再读取归档日志文件,转而读取SRL文件。
1.3. 应用服务(MRP)
MRP进程在库自动应用redo记录来维护与主库的同步,允许对数据的事务性一致访问。默认应用服务需要等待SRL归档之后才应用redo,当然也可以启动实时应用,允许应用服务应用当前SRL的redo记录。
1.4. 保证实时同步的条件
保证实时同步的必要条件:
– the standby redo logs are the same size as the online redo logs, and
– there are (( # of online logs per thread + 1) * # of threads) standby redo logs.
2. 出问题的分析步骤
一般出现问题了,我们可以去查几个数据字典:
2.1. 查询进程是否正常: gV$MANAGED_STANDBY
SELECT PROCESS, STATUS, THREAD#, SEQUENCE#, BLOCK#, BLOCKS ,CLIENT_PID, pid FROM gV$MANAGED_STANDBY WHERE THREAD#!=0 ORDER BY THREAD#, SEQUENCE#
- 通过上面的语句在主库判断LNS进程是否正常,主库也可以直接在操作系统上查看lns进程是否存在:
ps -ef|grep -v grep|grep -E "ora_lns|ora_nsa|ora_nss"
- 在备库判断MRP进程是否正常:备库进程如下,有MRP进程(wait for log),没有发现RFS进程工作,也可以理解为当前没有数据传输 ing 。
-
正常情况下主库查询备用数据库应用模式:
SELECT RECOVERY_MODE FROM V$ARCHIVE_DEST_STATUS WHERE DEST_ID=2;
RECOVERY_MODE
-----------------------
MANAGED REAL TIME APPLY
如果是非实时,则显示为MANAGED
- 正常情况备库一直实时应用,应该类似如下:
col BLOCKS for 999999999999999
col client_process for a15
col CLIENT_PID for a15
col STATUS for a15
SELECT INST_ID, PROCESS, PID, CLIENT_PROCESS, CLIENT_PID, STATUS, THREAD#, SEQUENCE#, BLOCK#, BLOCKS
FROM GV$MANAGED_STANDBY
WHERE THREAD#!=0 ORDER BY THREAD#, SEQUENCE#;
INST_ID PROCESS PID CLIENT_PROCESS CLIENT_PID STATUS THREAD# SEQUENCE# BLOCK# BLOCKS
--------- --------- ---------------- --------------- --------------- --------------- -------- --------- ---------------- ----------------
1 ARCH 143191 ARCH 143191 CLOSING 1 5599 1 6
1 ARCH 143189 ARCH 143189 CLOSING 1 5600 3473408 1446
1 ARCH 143195 ARCH 143195 CLOSING 1 5602 3682304 553
1 RFS 144485 LGWR 204820 IDLE 1 5603 1020933 3
1 MRP0 144706 N/A N/A APPLYING_LOG 1 5603 1020935 4194304
在alert日志中应该:
Primary database is in MAXIMUM PERFORMANCE mode.
Media Recovery Log /u01/arch/1_100_xxxx.dbf
Media Recovery Log /u01/arch/1_101_xxxx.dbf
Media Recovery Log /u01/arch/1_102_xxxx.dbf
Media Recovery Log /u01/arch/1_103_xxxx.dbf
Media Recovery Waiting for thread 1 sequence 489 (in transit)
2.2. 查询是否实时应用gv$dataguard_stats
set lines 200
col ctime format a20
col value format a20
select inst_id,to_char(sysdate,'yyyymmdd hh24:mi:ss') ctime,name,value,datum_time from gv$dataguard_stats where name like '%lag';
最近遇到的一个问题:
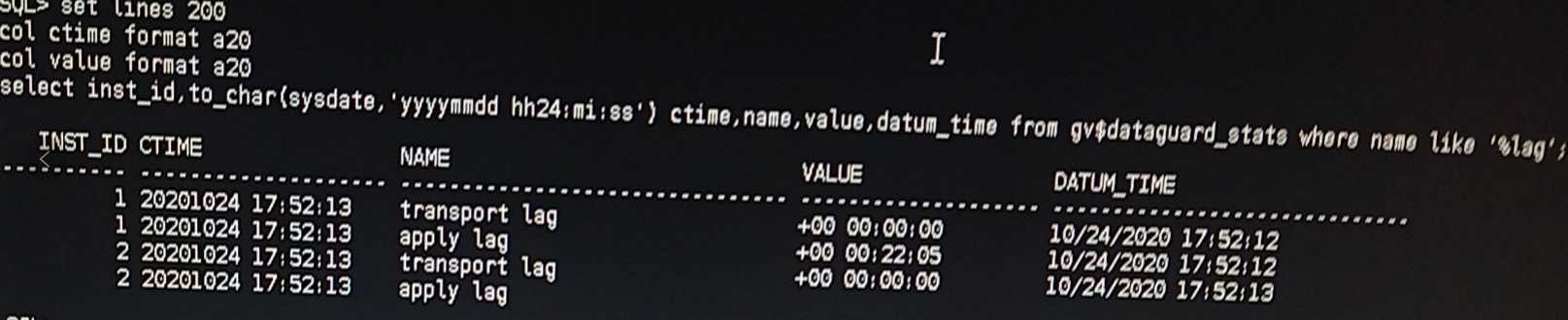
可以很明显的看到是:传输没有问题,实时应用出了问题,那么就应该去找实时应用为什么不“实时”了
2.3. ORA-16191
一般出现密码问题,可以先去主库修改一下sys的密码,然后将orapwd文件分发到备库上去。
2.4. alert提示看trace
alert里面提示了看trace,但没有写具体的路径,如下
FAL[server, ARC8]: FAL archive failed, see trace file.
那这个trace文件的名字应该是 instid_ARC8_xxxx.trc 和 instid_ARC8_xxxx.trm
2.5. 遇到间歇性不通
可以将dest先defer再enable试试。也可以切一下主库的所有实例的日志看下alert有没有报错
ALTER SYSTEM ARCHIVE LOG CURRENT;
3. 数据字典
3.1. FAL_CLIENT和FAL_SERVER
FAL_CLIENT和FAL_SERVER是配置dataguard用到的两个参数,FAL指获取归档日志(Fetch Archived Log),这两个参数只需在standby库设置。
在一定的条件下,或者因为网络失败,或者因为资源紧张,会在primary和standby之间产生裂隙,也就是有些归档日志没有及时的传输并应用到standby库。因为MRP(managed recovery process)/LSP(logical standby process)没有与primary直接通讯的能力来获取丢失的归档日志。因此这些gaps通过FAL客户和服务器来解决,由初始化参数定义FAL_CLIENT和FAL_SERVER。
FAL_SERVER指定一个Oracle Net service name,standby数据库使用这个参数连接到FAL server,这个参数适用于standby站点。比如,FAL_SERVER = PrimaryDB,此处PrimaryDB是一个TNS name,指向primary库。-
FAL_CLIENT指定一个FAL客户端的名字,以便FAL Server可以引用standby库,这也是一个TNS name,primary库必须适当配置此TNS name指向stanby库。这个参数也是在standby库端设置。比如,FAL_CLIENT = StandbyDB,StandbyDB是standby库的TNS name。
–FAL_CLIENT和FAL_SERVER应该成对设置或改变。
3.2. v$dataguard_stats
这个动态视图一般用来查看备库到主库的应用日志延迟时间。
| 字段名 | 作用 |
|---|---|
| APPLY LAG | 只与应用日志的实例有关,也就是 对于已经传到备库的redo来说,需要应用这部分redo日志需要的应用时间),备库通过应用主库传过来的redo日志与主库同步所延迟的时间。 |
| TRANSPORT LAG | 没有传到备库的redo量或者在已经传输到备库但是备库没有应用的redo量。 |
| APPLY FINISH TIME | 表示在备库上完成redo应用所需要的时间。从主数据库已经接收到了,但是没有应用的重做日志 所需的时间估计。 |
| ESTIMATED STARTUP TIME | 启动和打开物理备库需要的时间,不适用逻辑备库 |
| standby has been open | 该值表示物理备库自从上次启动以来,是否以OPEN READ ONLY方式打开过。该参数值如果是Y,现在需要做FAILOVER,那么就需要先将该物理备库shutdown然后以OPEN READ WRITE方式打开。 |
| TIME_COMPUTED | 物理备库上估算各个参数的本地时间 |