Kubernetes 日志收集
Kubernetes 集群本身不提供日志收集的解决方案,一般来说有主要的3种方案来做日志收集:
- 在节点上运行一个 agent 来收集日志
- 在 Pod 中包含一个 sidecar 容器来收集应用日志
- 直接在应用程序中将日志信息推送到采集后端
节点日志采集代理

通过在每个节点上运行一个日志收集的 agent 来采集日志数据,日志采集 agent 是一种专用工具,用于将日志数据推送到统一的后端。一般来说,这种 agent 用一个容器来运行,可以访问该节点上所有应用程序容器的日志文件所在目录。
由于这种 agent 必须在每个节点上运行,所以直接使用 DaemonSet 控制器运行该应用程序即可。在节点上运行一个日志收集的 agent 这种方式是最常见的一直方法,因为它只需要在每个节点上运行一个代理程序,并不需要对节点上运行的应用程序进行更改,对应用程序没有任何侵入性,但是这种方法也仅仅适用于收集输出到 stdout 和 stderr 的应用程序日志。
sidecar 容器收集日志
上面第一种方法可以看到有一个明显的问题就是采集的日志都是通过输出到容器的 stdout 和 stderr 里面的信息,这些信息会在本地的容器对应目录中保留成 JSON 日志文件,所以直接在节点上运行一个 agent 就可以采集到日志。但是如果应用程序的日志是输出到容器中的某个日志文件的话呢?这种日志数据显然只通过上面的方案是采集不到的了。
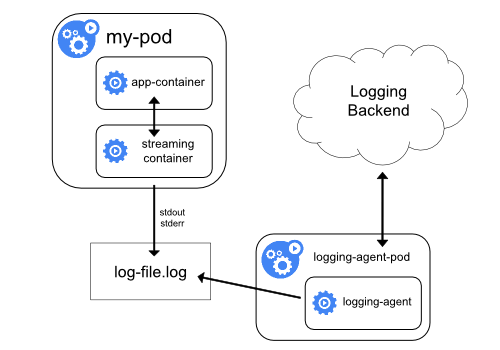
对于上面这种情况我们可以直接在 Pod 中启动另外一个 sidecar 容器,直接将应用程序的日志通过这个容器重新输出到 stdout,这样通过上面的节点日志收集方案又可以完成了。
由于这个 sidecar 容器的主要逻辑就是将应用程序中的日志进行重定向打印,所以背后的逻辑非常简单,开销很小,而且由于输出到了 stdout 或者 stderr,所以我们也可以使用 kubectl logs 来查看日志了。
示例:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
由于 Pod 中容器的特性,我们可以利用另外一个 sidecar 容器去获取到另外容器中的日志文件,然后将日志重定向到自己的 stdout 流中,可以将上面的 YAML 文件做如下修改:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
这样前面节点上的日志采集 agent 就可以自动获取这些日志信息,而不需要其他配置。
这种方法虽然可以解决上面的问题,但是也有一个明显的缺陷,就是日志不仅会在原容器文件中保留下来,还会通过 stdout 输出后占用磁盘空间,这样无形中就增加了一倍磁盘空间。
使用 sidecar 运行日志采集 agent
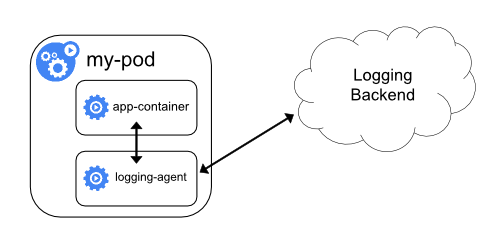
如果觉得在节点上运行一个日志采集的代理不够灵活的话,那么也可以创建一个单独的日志采集代理程序的 sidecar 容器,不过需要单独配置和应用程序一起运行。
不过这样虽然更加灵活,但是在 sidecar 容器中运行日志采集代理程序会导致大量资源消耗,因为如果有多少个要采集的 Pod,就需要运行多少个采集代理程序,另外还无法使用 kubectl logs 命令来访问这些日志,因为它们不受 kubelet 控制。
举个例子,可以使用的Stackdriver,它使用fluentd作为记录剂。以下是两个可用于实现此方法的配置文件。第一个文件包含配置流利的ConfigMap。
下面是 Kubernetes 官方的一个 fluentd 的配置文件示例,使用 ConfigMap 对象来保存:
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
上面的配置文件是配置收集原文件 /var/log/1.log 和 /var/log/2.log 的日志数据,然后通过 google_cloud 这个插件将数据推送到 Stackdriver 后端去。
下面是我们使用上面的配置文件在应用程序中运行一个 fluentd 的容器来读取日志数据:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config